Is double open coding possible? Here in the Hipster project, we have found that not only is the answer ‘yes’, but also that the benefits are considerable. Read on to learn why
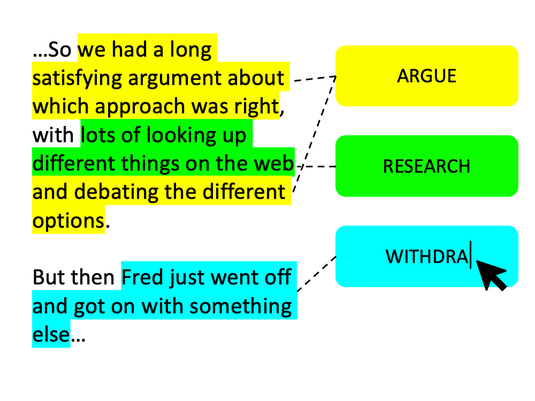
Coding is an important research technique. Not to be confused with coding as writing software, coding in research is a way of analysing a large corpus, usually of text. A typical corpus might be a set of transcribed interviews, or a collection of academic papers. Researchers use codes to highlight sections of text that have particular implications for the research. For example, if we were analysing some interviews to establish how programmers behave, we might use open coding, looking for different types of behaviour in the text, creating codes to describe each behaviour, and highlighting the text that corresponds to each code. For example, in the picture the researcher has already defined codes for Argue and Research, and is now creating a new code for a further behaviour: Withdraw.
This Open coding is used for research where the researchers do not know in advance what to expect. It is often used to answer open questions such as “How do programmers behave?” . Grounded Theory, a method often used in IT research, uses open coding to construct new theories that are grounded in existing data.
Some researchers still code by printing out all the corpus text and using highlighter pens, assigning a different colour to each code. Most, nowadays, use a Qualitative Data Analysis (QDA) tool, such as NVivo or Atlas.ti. That allows them to combine coding from more than one researcher. Indeed, best practice nowadays requires such dual coding, to promote objectivity and the benefits of multiple viewpoints—at least for closed coding, where the codes are predefined.
In the Hipster project, we decided to take this best practice a stage further, by having two coders carry out open coding on a corpus. But how were we to do that when each coder must work on a separate copy of the corpus, and each coder can create new codes ‘on the fly’? We checked the literature, and found few references to dual open coding—and no instructions. So, we worked out something for ourselves.
The trick, we found, turns out to be do the coding iteratively. We code in cycles. In each cycle, we agree a portion of the corpus (typically a particular set of interviews or papers) to code. Then each coder goes away and codes that portion independently in their own copy of the corpus, creating new open codes as required. And finally, we meet, merge the two copies, and use the QDA tool to explore in detail what new codes have been created, where the coding is similar, and where it differs.
And in that meeting, behold, learning happens! It is in that discussion that we might find that we have interpreted some statements in diametrically opposite ways; that some statements are ambiguous, or that they offer remarkable insights into the research topic. As we discuss, we sometimes find we have given different names to the same concept; or we might agree that one code is overloaded and really covers two different concepts. Or we might identify other information we may need to capture to support the research: information about interviewees, for example.
The discussion often serves also to recall us to the original purpose of the coding; it is easy to get side-tracked from the original research questions, but discussing the research often recalls us to the main purpose and therefore to the reasons to create codes, or not. And as we discuss, we figure out fixes for the issues. We might combine the two codes for the same concept, or split up the overloaded code. We might create a new code to capture the extra information we identified.
Following the meeting, one researcher then carries out the agreed changes, and we then each take a new copy of the resulting data file for further coding. And the cycle starts again.
We find this dual open coding approach has several benefits:
- It’s easy to miss sophisticated concepts while coding; with two coders it is more likely that one or the other will notice;
- It focusses the process and keeps the research on track;
- The discussion often leads to new ideas, new ways of approaching aspects of the research, and new groupings of codes; and
- If a concept has meaning for two people, it is likely to be understood by others. So, there is more clarity to the concepts involved, and they are more likely to be meaningful to readers of the resulting research papers.
Yet, dual open coding has some disadvantages, of course:
- The basic coding effort is twice what it might take one person; and
- Between each cycle there must be a meeting. Waiting for a chance to have a meeting before coding the next batch means that the elapsed time required to code the whole corpus can become quite large.
Coding does not necessarily take very long: one experienced coder estimates it to be about real time – coding an hour’s interview takes an hour. I find my coding is generally slower, but rarely less than half that speed. So, the effort cost of double coding is small compared with, for example, the effort to set up and carry out interviews or to find literature; and certainly is small compared with the time needed to write up the research as an academic paper. The elapsed time problem is certainly an issue, but in the timescales of normal academic research we have found the delays acceptable. And the benefit, in terms of better analysis, is huge.
In fact, double open coding can be a great investment into better research outcomes.
Could you be double open coding soon?
- Charles